
What is metadata and why is it as important as the data itself?
Understanding the importance of metadata and putting the right strategy in place is vital to effective data sharing and reuse via data product marketplaces, enabling AI deployments and wider data democratization. Our comprehensive blog explains what metadata is, outlines its benefits and shares best practice for your strategy.

Metadata plays an essential role in managing the growing volumes of data within organizations. Indispensable for structuring, organizing, and enhancing the value of information, it makes data easier to search, understand, and reuse.
Implementing an effective metadata management strategy has therefore become a key priority for all companies that aim to democratize data usage, improve the efficiency of their data product marketplaces, and drive AI.
What is metadata?
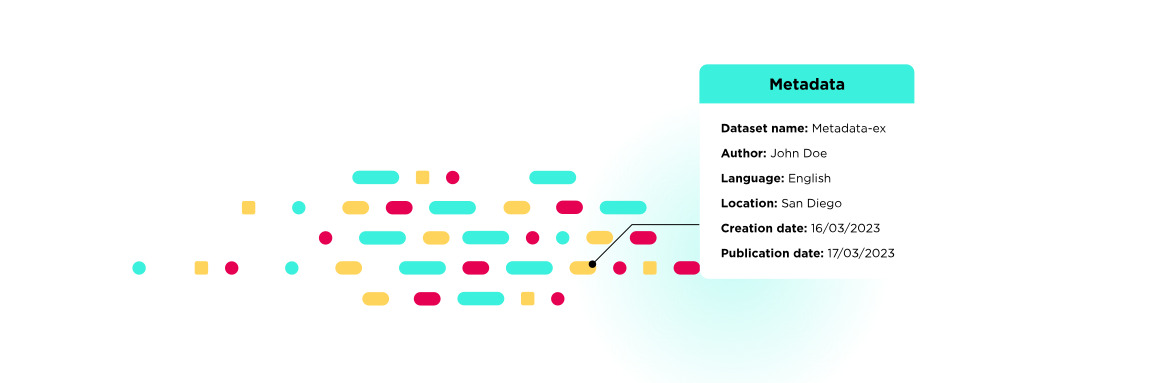
Metadata refers to “data that describes other data.” Essentially it is a shorthand representation of the data to which it refers. It doesn’t tell you what the content is, but instead describes the type of thing that it is.
Metadata summarizes the basic information about data in order to make it easier to search, manage, and use. It helps explain its provenance, its origin, nature, structure, and lineage. That means if someone (human or AI) has never seen a particular dataset before they can immediately understand what it covers and how it has been created or collected by reviewing the metadata. Metadata can include:
- The data owner
- A summary of what the data contains
- The location of the data
- The creation and/or update date
- The data source
- The purpose of the data
This means that it is possible to understand what a data product, a dataset, a visualization, or an API covers simply by consulting the metadata.
A good analogy is a book, the data is the content of the book itself, while the metadata is the title, format, publication date, author and the book’s subject.
Where is metadata managed?
Metadata is generally managed in data catalogs, which inventory all the metadata within an organization. Each dataset is described so it can be linked to others.
Metadata is also visible in all data management tools within an organization, as it not only describes the data but also defines its framework.
In a data product marketplace, metadata provides a first overview that helps users decide whether they want to explore further.
Why is metadata important?
We live in a data-centric world, powered by information. Organizations create and collect increasing volumes of data, from a wide range of systems, software and sensors. This data is typically delivered in a range of different formats.This all makes it difficult to compare or use datasets with confidence internally, externally or in AI solutions.
Metadata acts as a universal language that provides more details about datasets—such as units of measurement, update frequency, or data ownership. It is therefore essential for inventorying and organizing information so that it can be compared and reused.
Metadata is just as important as the data itself. It ensures optimal searchability and understanding of information, while supporting good governance. This is crucial for enabling employees, partners and AI to access and reuse data confidently in their working lives. Additionally, metadata reduces the time and effort spent searching for information and helps avoid unnecessary downloads. Metadata is essential to both training Large Language Models and underpinning agentic AI.
That’s why metadata is especially important within centralized data product marketplaces. By describing data products and other data assets metadata ensures that they can be discovered easily and understood by any user in terms of what they cover, enabling interoperability. Metadata viewers provide an overview of the metadata attached to each data asset.
Thanks to metadata, data published in data product marketplaces and data management tools gains clarity, quality, —for both humans and technology, including artificial intelligence (AI) tools. It is key to optimizing governance, data quality, compliance, and consumption.
What are the objectives of metadata?
Metadata meets multiple objectives and facilitates the discovery, understanding, and reuse of data. It covers eight key characteristics:
- Provides context: Explains what the data covers, themes, keywords, collection method, etc. This also includes numerical units (e.g., dollars, inches, centimeters)
- Ensures uniqueness: Differentiates datasets from similar ones so users can identify the most relevant information for their needs
- Provides a usage framework: Includes information on licensing, internal or external reuse conditions, and organizational rules (e.g., authorized users)
- Promotes reuse: Provides complete and clear descriptions, including available formats and potential reuse cases
- Facilitates interoperability: Complies with internal or external standards so data can be confidently compared with other datasets. Field descriptions and formats (such as dates) should be standardized
- Ensures reliability: Includes details about the source, update frequency, and content
- Enables easy access (for humans and machines): Uses standardized terms so data can be easily found via internal data marketplaces or search engines. High-quality metadata also supports AI model training and algorithm learning
- Ensures longevity: Since data may be shared and stored in multiple places, metadata should include stable contact details (e.g., a team name rather than an individual employee’s name)
What are the different types of metadata?
Although metadata descriptions seem limitless, four main categories of metadata schemas exist:
- Descriptive metadata: Details about the data itself: name, content, theme, creator, etc.
- Structural metadata: Information about classification and format, facilitating access and reuse
- Administrative metadata: Information related to rights management and licensing
- Relational metadata: Information describing how datasets are linked to other data and how they evolve, helping monitor data lineage
What are the benefits of metadata?
Without metadata sharing information at scale is virtually impossible. Metadata helps avoid confusion when comparing or combining datasets. It provides seven key benefits:
-
- Facilitates data discovery, sharing, and reuse on data marketplaces and portals
- Improves decision-making by making data more organized and comparable for both humans and AI
- Supports effective data governance and ensures compliance with company policies
- Enhances data quality by providing information on reliability and accuracy
- Saves time and increases efficiency by enabling users to find relevant data quickly without relying on data teams
- Encourages internal and external collaboration through shared and well-understood data
- Ensures compliance and interoperability across systems by maintaining updated records and tracking changes
Metadata models and standards
The W7 Ontological Model of Metadata
In their book A semiotic Framework for Analyzing Data Provenance Research, Liu and Ram define a conceptual model in seven parts. Most metadata schemas are based on these interconnected questions:
- What: What does the dataset cover?
- When: What time period does it cover?
- Where: What is its geographic or spatial coverage?
- Who: Who created it (organization, team, individual)?
- How: How can it be used? What are the licensing conditions?
- Which: Which source generated it (software, sensor, machine)?
- Why: Why does the dataset exist? Why was it created and shared?
Metadata standards
While the idea of metadata is simple in principle, the concept of applying metadata to your datasets can seem daunting. Where do you start? How do you describe your data so that it is consistent and can be shared internally and externally? How do you scale your program?
To help, a number of international standards have been formulated and agreed. These include the Dublin Core standard, the W3C Data Catalog Vocabulary (DCAT), and the EU’s INSPIRE framework for spatial data. These are based on agreed ISO standards to ensure interoperability and wide reuse.
Huwise natively integrates an effective metadata management tool into its data product marketplace solution to boost the discoverability of data at scale within the organization. There are three categories of metadata templates within the platform, each with associated benefits:
- Standard models: Customized to organizational requirements (classification, sector, specific vocabulary)
- Interoperability models (non-editable): Ensuring compliance with international standards such as DCAT, DCAT-AP, INSPIRE, or Dublin Core
- Administrative models: Visible only to portal administrators to ensure strong internal governance
Metadata and ontologies
Ontologies are descriptions and definitions of relationships and can complement metadata. Ontologies can include some or all of the following descriptions/information:
- Classes (general elements or types)
- Instances (individual objects)
- Relationships between objects
- Object properties
- Functions, processes, constraints, and rules
Ontologies help us to understand the relationship between objects. As an example, an “Android phone” belongs to the object class, “cell phone”.
In metadata schemas, ontologies enhance interoperability by defining dataset structure, covered fields, and information types (e.g., numeric values). This is reflected in metadata through standardized definitions for each column header type.
Metadata and the data product marketplace
In a data product marketplace, metadata plays a key role in providing context and clarity for users and data consumers. It does more than document datasets—it forms the foundation for search functionality and can be transformed into filters that allow users to explore catalogs based on relevant criteria.
With Huwise, metadata management is simplified:
- A dedicated section to clearly display metadata that is fully customizable
- Huwise metadata models feature intuitive interfaces and detailed instructions to guide users to complete fields correctly and thoroughly
- The Automation API, which enables large-scale metadata management, ensuring that any modification is instantly reflected across all organizational tools—keeping information reliable and up to date

"Thanks to Huwise’s metadata management feature, we implemented a customized data model that enables us to efficiently manage our specific metadata (such as update frequency, confidentiality level, and the names of data owners or data stewards). As a result, the operational management of our platforms has been optimized, and data updates have been simplified—giving us real autonomy and allowing us to save valuable time. In addition, configuring the models is simple and intuitive, particularly thanks to the ability to make certain fields mandatory in the template to prevent data entry errors."

Best practices to improve data reuse through metadata
To promote effective data sharing and reuse through data product marketplaces, key metadata management best practices should be followed:
- Define a metadata management strategy aligned with your organization’s data-sharing objectives
- Gather and understand user needs and potential use cases
- Prioritize adding metadata to the most valuable data assets to drive their usage
- Involve relevant data owners and users by creating a cross-functional team responsible for metadata management
- Establish a metadata classification system and create a shared vocabulary based on recognized standards
- Raise awareness among all data owners about the importance of metadata and clearly communicate standards, practices, templates, and processes
- Monitor compliance with metadata standards and update them when necessary
The importance of metadata to data sharing and AI
Metadata plays a key role in increasing data consumption by humans and AI by enhancing reliable access to trusted data for both expert and non-expert users. All of this means that within an organization, your metadata management strategy must be comprehensive and aligned with defined standards to encourage effective data reuse, and underpin AI success.
Find out more about metadata management in our ebook.
- Dugas, M., et al. “Memorandum ‘Open Metadata’.” Methods of information in medicine 54.4 (2015): 376-378.
- Detken, Kai-Olivier, Dirk Scheuermann, and Bastian Hellmann. “Using Extensible Metadata Definitions to Create a Vendor-Independent SIEM System.” International Conference in Swarm Intelligence. Springer International Publishing, 2015.
- Jiang, Guoqian, et al. “Using Semantic Web Technologies for the Generation of Domain-Specific Templates to Support Clinical Study Metadata Standards.” Journal of biomedical semantics 7.1 (2016): 1.
- McCrae, John P., et al. “One Ontology to Bind Them All: The META-SHARE OWL ontology for the Interoperability of Linguistic Datasets on the Web.” European Semantic Web Conference. Springer International Publishing, 2015.
- Riechert, Mathias, et al. “Developing Definitions of Research Information Metadata as a Wicked Problem? Characterisation and Solution by Argumentation Visualisation.” Program 50.3 (2016).
- S. Ram and J. Liu, “A Semiotics Framework for Analyzing Data Provenance Research,” Journal of Computing Science and Engineering, vol. 2, pp. 221-248, 2008.)
- Wilson, Samuel P. “Developing a metadata repository for distributed file annotation and sharing.” Diss. PURDUE UNIVERSITY, 2015.
Other Discussions on Ontologies and Ontology
- Polleres, Axel and Simon Steyskal. “Semantic Web Standards for Publishing and Integrating open data.”Standards and Standardization: Concepts, Methodologies, Tools, and Applications (2015): 1.
- Daraio, Cinzia, et al. “The advantages of an Ontology-Based Data Management Approach: Openness, Interoperability, and Data Quality.” Scientometrics (2016): 1-15.
- Fukuta, Naoki. “Toward an Agent-Based Framework for Better Access to open data by Using Ontology Mappings and their Underlying Semantics.” Advanced Applied Informatics (IIAI-AAI), 2015 IIAI 4th International Congress. IEEE, 2015.
Share this post:
Articles on the same topic:
About the author

Lauréline Saux
Lauréline Saux is passionate about the democratization of data and its impact on society. Through the content she writes, she analyzes the trends and challenges that impact the world of data.
More articles

